
Database Testing: An Introduction to Database Testing
Table of Contents
- Why database testing?
- What should we test?
- When should we test?
- Automated database regression testing
- Who should test?
- Introducing database testing into your organization
- Database testing and data inspection
- Test-driven database development (TDDD)
- Effective practices
- Related Resources
1. Why Database Testing?
There are several reasons why you need to develop a comprehensive testing strategy for your RDBMS:
- Data is an important corporate asset. Doesn’t it make sense to invest the effort required to validate the quality of data via effective testing?
- Databases implement mission-critical business functionality. This functionality should be properly tested regardless of the technology used to implement it.
- Traditional data quality approaches aren’t sufficient. I’ll let the current state of data quality (DQ) speak for itself.
- Testing provides the concrete feedback required to identify defects. How do you know how good the quality of your source data actually is without an effective test suite which you can run whenever you need to?
- Support for evolutionary development. Many evolutionary development techniques, in particular database refactoring, are predicated upon the idea that it must be possible to determine if something in the database has been broken when a change has been made. The easiest way to do that is to simply run your regression test suite.
Here are some interesting questions for people not convinced of the need for database testing:
- If you’re implementing code in the DB in the form of stored procedures, triggers, … shouldn’t you test that code to the same level that you test your app code?
- Think of all the data quality problems you’ve run into over the years. Wouldn’t it have been nice if someone had originally tested and discovered those problems before you did?
- Wouldn’t it be nice to have a test suite to run so that you could determine how (and if) the DB actually works?
I think that one of the reasons that we don’t hear much about database testing is because it is a relatively new idea within the data community. Many traditional data professionals seem to think that testing is something that other people do, particularly test/quality assurance professionals, do. This reflects a penchant for over-specialization and a serial approach towards development by traditionalists, two ideas which have also been shown to be questionable organizational approaches at best.
2. What Should We Test?
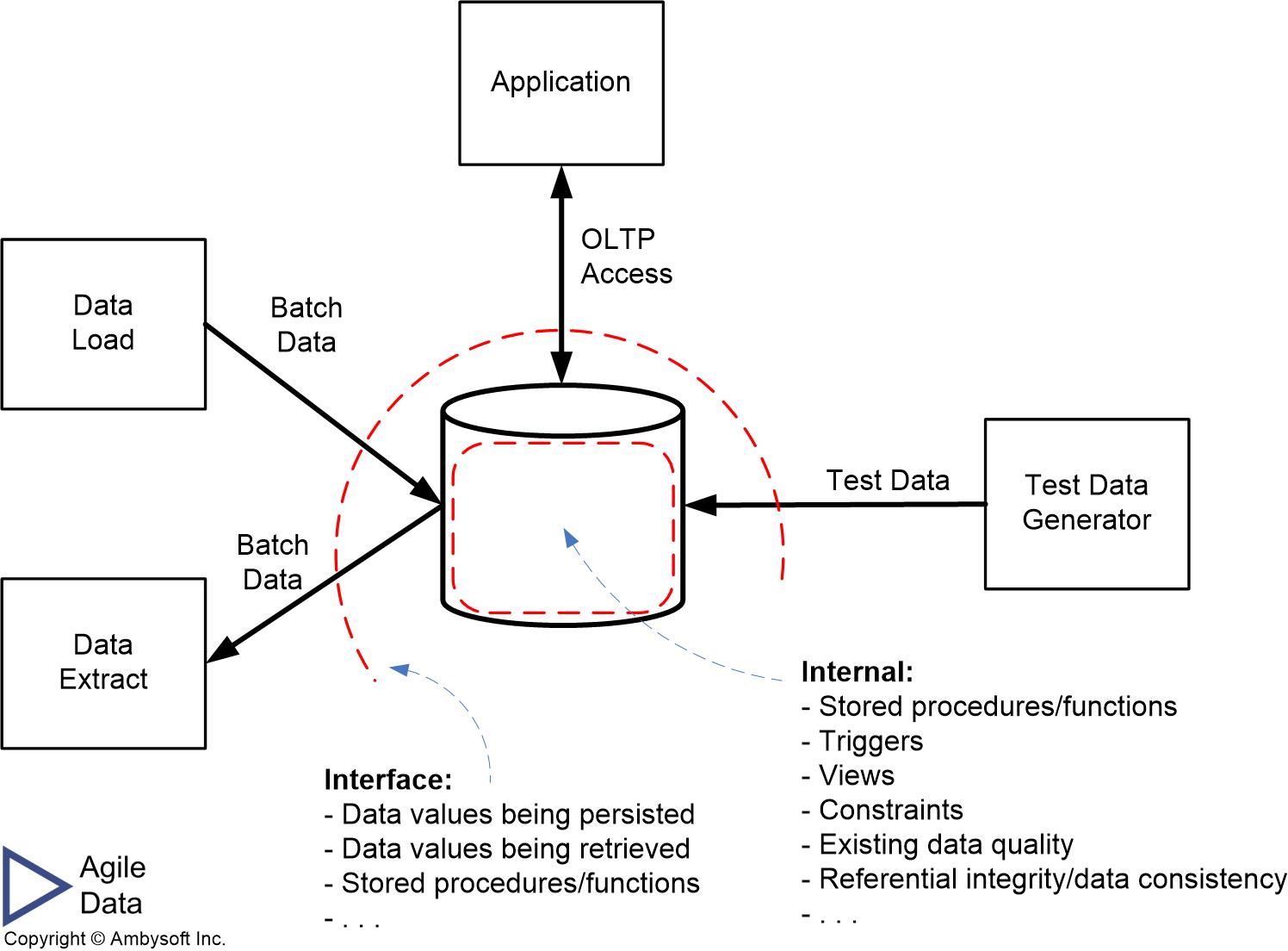
Figure 1 indicates what you should consider testing when it comes to relational databases. The reflects the context of a single database, the dashed lines indicate threat boundaries, indicating that you need to consider threats both within the database (internal testing) and at the interface to the database (interface/black box testing). For details, read the article What To Test in a Database.
Figure 1. What to test in a database (click to enlarge).
3. When Should We Test?

4. Automated Database Regression Testing
Automated database regression testing is the act of running a test suite on a regular basis, ideally whenever a developer or data engineer has done something which could potentially inject a defect into the implementation of a database. For details, please read Database Testing: Automated Database Regression Testing.
5. Who Should Test?
During development cycles, the primary people responsible for doing database testing are application developers and Agile data engineers. They will typically pair together, and because they are hopefully taking a TDD-approach to development the implication is that they’ll be doing database unit testing on a continuous basis. During the release cycle your testers, if you have any, will be responsible for the final system testing efforts and therefore they will also be doing database testing.
The role of your data management (DM) group, or IT management if your organization has no DM group, should be to support your database testing efforts. They should promote the concept that database testing is important, should help people get the requisite training that they require, and should help obtain database testing tools for your organization. Database testing is something that is done continuously by the people on development teams, not something performed by another group (except of course for system testing efforts). In short, the DM group needs to support database testing efforts and then get out of the way of the people who are actually doing the work.
6. Introducing Database Regression Testing into Your Organization
Database testing is new to many people, and as a result you are likely to face several challenges:
- Insufficient testing skills. This problem can be overcome through training, through pairing with someone with good testing skills (pairing a data engineer without testing skills and a tester without data engineering skills still works), or simply through trial and error. The important thing is that you recognize that you need to pick up these skills.
- Insufficient unit tests for existing databases. Few organizations have yet to adopt the practice of database testing, so it is likely that you will not have a sufficient test suite for your existing database(s). Although this is unfortunate, there is no better time than the present to start writing your test suite.
- Insufficient database testing tools. As I said earlier, we still have a way to go with respect to tools.
- Reticent DM groups. My experience is that some data management (DM) groups may see the introduction of database regression testing, and agile techniques such as test-first development (TFD) and refactoring, as a threat. Or, as my July 2006 “state of data management” survey shows, a large percentage of organizations are not only not doing any database testing at all they haven’t even discussed it. For many in the data management community the idea of doing database testing is rather new and it’s simply going to take a while for them to think it through. I’m not so sure that you should wait to do such obvious process improvement.
In general, I highly suggest that you read my article Adopting Evolutionary/Agile Database Techniquesand consider buying the book Fearless Change which describes a pattern language for successfully implementing change within organizations.
7. Database Testing and Data Inspection
A common quality technique is to use data inspection tools to examine existing data within a database. You might use something as simple as a SQL-based query tool such as DB Inspect to select a subset of the data within a database to visually inspect the results. For example, you may choose to view the unique values in a column to determine what values are stored in it, or compare the row count of a table with the count of the resulting rows from joining the table with another one. If the two counts are the same then you don’t have an RI problem across the join.
As Richard Dallaway points out, the problem with data inspection is that it is often done manually and on an irregular basis. When you make changes later, sometimes months or years later, you need to redo your inspection efforts. This is costly, time consuming, and error prone.
Data inspection is more of a debugging technique than it is a testing technique. It is clearly an important technique, but it’s not something that will greatly contribute to your efforts to ensure data quality within your organization.
8. Test Driven Database Development (TDDD)
Agile software developers take a test-first approach to development where they write a test before you write just enough production code to fulfill that test. Figure 3 depicts the steps of test first development (TFD). The first step is to quickly add a test, basically just enough code to fail. You then update your functional code to make it pass the new test. The third step is to run your tests again. If they fail you need to update your functional code and retest. Once the tests pass you iterate and add another test.
Figure 3. The process of Test First Development (TFD) – Click to enlarge.

Test-driven development (TDD) is an evolutionary approach to development which combines test-first development and refactoring. When an agile software developer goes to implement a new feature, the first question they ask themselves is “Is this the best design possible which enables me to add this feature?” If the answer is yes, then they do the work to add the feature. If the answer is no then they refactor the design to make it the best possible then they continue with a TFD approach. This strategy is applicable to developing both your application code and your database schema, two things that you would work on in parallel.When you first start following a TDD approach to development you quickly discover that to make it successful you need to automate as much of the process as possible? Do you really want to manually run the same build script(s) and the same testing script(s) over and over again? Of course not. So, agile developers have created OSS tools such as ANT, Maven, and Cruise Control (to name a few) which enable them to automate these tasks. More importantly, it enables them to automate their database testing script into the build procedure itself.Agile developers realize that testing is so important to their success that it is something they do every day, not just at the end of the lifecycle, following agile testing strategies. They test as often and early as possible, and better yet they test first.
9. Effective Practices for Database Testing
I’d like to share a few database testing “best practices” with you:
- Use an in-memory database for regression testing. You can dramatically speed up your database tests by running them, or at least portions of them, against an in-memory database such as HSQLDB. The challenge with this approach is that because database methods are implemented differently across database vendors that any method tests will still need to run against the actual database server.
- Start fresh each major test run. To ensure a clean database, a common strategy is that at the beginning of each test run you drop the database, then rebuild it from scratch taking into account all database refactorings and transformations to that point, then reload the test data, and then run your tests. Of course, you wouldn’t do this to your production database. 😉
- Take a continuous approach to regression testing. I can’t say this enough, a TDD approach to development is an incredibly effective way to work.
- Train people in testing. Many developers and date engineers have not been trained in testing skills, and they almost certainly haven’t been trained in database testing skills. Invest in your people, and give them the training and education they need to do their jobs.
- Pair novices with people that have database testing experience. One of the easiest ways to gain database testing skills is to pair program with someone who already has them.
10. Parting Thoughts
Isn’t it time that we stopped talking about data quality and actually started doing something about it?
10. Related Resources
- Automated Database Regression Testing
- The Agile Database Techniques Stack
- Clean Database Design
- Continuous Database Integration (CDI)
- Data Debt: Understanding Enterprise Data Quality Problems
- Database Testing Terminology: A Glossary of Terms
- Introduction to DataOps: Bringing Databases Into DevOps
- Introduction to Test-Driven Development (TDD)
- What To Test in a Database