
Implementing Referential Integrity and Shared Logic in a RDB
Referential integrity (RI) refers to the concept that if one entity references another, then that other entity actually exists. For example, if I claim to live in a house at 123 Main Street, then that house must actually be there; otherwise, we have an RI error. In relational database design, the referential integrity rule (Halpin 2001) states that each non-null value of a foreign key must match the value of some primary key.
In the 1970s, when relational databases first came on the scene, the standard implementation technology was procedural languages such as PL/1, Fortran, and COBOL. Because these languages didn’t implement anything similar to data entities and because the relational database did it made sense that relational databases be responsible for ensuring referential integrity. Furthermore relational databases back then were relatively simple, they stored data and supported the ability to implement basic RI constraints. The end result was that business logic was implemented in the application code and RI was implemented in the database. Modern software development isn’t like this anymore. We now work with implementation languages such as C# and Java that implement entities called classes. As a result referential integrity also becomes an issue within your application code as well as in your database. Relational database technology has also improved dramatically, supporting native programming languages to write stored procedures and triggers and even standard object programming languages such as Java. It is now viable to implement business logic in your database as well as in your application code. The best way to look at it is that you now have options as to where referential integrity and business logic is implemented. This article explores the implications of this observation.
Table of Contents
1. How Object Technology Complicates Referential Integrity
Modern deployment architectures are complex. The components of a new application may be deployed across several types of machines, including various client machines, web servers, application servers, and databases. It is important to recognize that software development has become more complex over the years. One of the main reasons why the object-oriented paradigm was embraced so ardently by software developers is because it helped them to deal with this growing complexity. Unfortunately the solution, in this case the common use of object technology within an n-tier environment, has added a few complications with respect to ensuring referential integrity. In particular, there are several aspects of object technology that you need to come to terms with:
- Multiple entity representation
- Object relationship management
- Lazy reads
- Caches
- Association, aggregation, and composition
- Architectural layering
- Removal from memory vs. persistent deletions
1.1 Multiple Entity Representation
An entity can be represented in different ways. For example, customer data can be displayed on an HTML page, be used to create a customer object that resides on an application server, and be stored in the database. Keeping these various representations in sync is a concurrency control issue. Concurrency control is nothing new, it is something that you need to deal with in a multi-user system regardless of the implementation technology being used. However, when you are using object technology and relational technology together you are in a situation where you are implementing structure in two places: In your object schema as classes that have interrelationships and in your data schema as tables with interrelationships. You will implement similar structures in each place. For example you will have an Order object that has a collection of OrderItem object in your object schema and an Order table that is related to the OrderItem table. It should be obvious that you need to deal with referential integrity issues within each schema. What isn’t so obvious is that because the same entities are represented in multiple schemas you have “cross schema” referential integrity issues to deal with as well.
Let’s work through an example using orders and order items. To keep things simple, assume that there is a straight one-to-one mapping between the object and data schemas. Also assume that we’re working with a fat-client architecture, built in Java, and a single database. We would have the same issues that I’m about to describe with an n-tier architecture that involves a farm of application servers, but let’s keep things simple. I read an existing order and its order items into memory on my computer. There are currently two order items, A and B. Shortly thereafter you read the exact same order and order items into memory on your computer. You decide to add a new order item, C, to the order and save it to the database. The order-order item structure is perfectly fine on each individual machine – my order object references two order item objects that exist it’s memory space, your order object references three order item objects that exist in its memory space, and the three rows in the OrderItem table all include a foreign key to the row in the Order table representing the order. When you look at it from the point of view of the entities, the order and its order items, there is an RI problem because my order object doesn’t refer to order item C.
A similar situation would occur if you had deleted order item B – now my order object would refer to an order item that no longer exists. This assumes of course that the database is the system of record for these entities. When something is changed in the system of record it’s considered an “official” change.
This concept is nothing new. When the same entities are stored in several databases you have the exact same referential integrity issues to deal with. The fundamental issue is that whenever the same entities are represented in several schemas, regardless of whether they are data schemas or object schemas, you have the potential for “cross schema” referential integrity problems.
1.2 Object Relationship Management
A common technique to ensure referential integrity is to use triggers to implement cascades. A cascade occurs when an action on one table fires a trigger that in turn creates a similar action in another table, which could in turn fire another trigger and so on recursively. Cascades, assuming the triggers are implemented correctly according to the applicable businesses, effectively support automatic relationship management. There are three common types of database cascades:
- Cascading deletes. The deletion of a row in the Customer table results in the deletion of all rows referring to the row in the CustomerHistory table. Each deletion from this table causes the deletion of a corresponding row, if any, in the CustomerHistoryNotes table.
- Cascading inserts. The insertion of a new row into the Customer table results in the insertion of a row into the CustomerHistory table to record the creation.
- Cascading updates. The update of a row in the OrderItem table results in an update to the corresponding row in the Item table to record a change, if any, in the current inventory level. This change could in turn trigger an update to the row in the DailyInventoryReorder table representing today’s reorder statistics that in turn triggers an update to the MonthlyInventoryReorder table.
Most reasonably sophisticated data modeling tools will automatically generate the stubs for triggers based on your physical data models. All you need to do is write the code that makes the appropriate change(s) to the target rows.
The concept of cascades is applicable to object relationships, and once again there are three types:
- Cascading deletes. The deletion of a Customer object results in the deletion of its corresponding Address object and its ZipCode object. In languages such as Java and Smalltalk that support automatic garbage collections cascading deletes, at least of the object in memory, is handled automatically. However, you will also want to delete the corresponding rows in the database that these objects are mapped to.
- Cascading reads. When an Order object is retrieved from the database you also want to automatically retrieve its OrderItem objects and any corresponding Item objects that describe the order items.
- Cascading saves. When an Order object is saved the corresponding OrderItem objects should also be saved automatically. This may translate into either inserts or updates into the database as the case may be.
You have several implementation options for object cascades, the choice of which should be driven by your database encapsulation strategy. First, you can code the cascades. This approach works well with a brute force, data access object, or service approach to database encapsulation. Second, your persistence framework may be sophisticated enough to support automatic cascades based on your relationship mapping metadata.
There are several important implications of cascades:
- You have an implementation choice. First, for a given relationship you need to decide if there are any cascades that are application and if so where you intend to implement them: in the database, within your objects, or both. You may find that you take different implementation strategies with different relationships. Perhaps the cascades between customers and addresses are implemented via objects whereas the cascades originating from order items are implemented in the database.
- Beware of cycles. A cycle occurs when a cascade cycles back to the starting point. For example a change to A cascades to B that cascades to C that in turn cascades back to A.
- Beware of cascades getting out of control. Although cascades sound great, and they are, there is a significant potential for trouble. If you define too many object read cascades you may find that the retrieval of a single object could result in the cascaded retrieval of thousands of objects. For example, if you were to define a read cascade from Division to Employee you could bring several thousand employees into memory when you read the object representing the manufacturing division in memory.
Table 1 summarizes strategies for when to consider defining object cascades on a relationship. For aggregation and composition the whole typically determines the persistence lifecycle of the parts and thus drives your choice of cascades. For associations the primary determining factor is the multiplicity of the association. For several situations, such as reading in a composition hierarchy, you almost always want to always do it. In other situations, such as deleting a composition hierarchy, there is a good chance that you want to implement a cascade and therefore I indicate that you should “consider” it. In the cases where you should consider adding a cascade you need to think through the business rules pertaining to the entities and their interrelationship(s) as well as how the entities are used in practice by your application.
Table 1. Strategies for defining object cascades.
| Relationship Type | Cascading Delete | Cascading Read | Cascading Save |
| Aggregation | Consider deleting the parts automatically when the whole is deleted. | Consider reading the parts automatically when the whole is read. | Consider saving the parts automatically when the whole is saved. |
| Association (one to one) | Consider deleting the corresponding entity when the multiplicity is 0..1.
Delete the entity when the multiplicity is exactly one. |
Consider reading the corresponding entity. | Consider saving the corresponding entity. |
| Association (one to many) | Consider deleting the many entities. | Consider reading the many entities. | Consider saving the many entities. |
| Association (many to one) | Avoid this. Deleting the one entity is likely not an option as other objects (the many) still refer to it. | Consider reading in the one entity. | Consider saving the one entity. |
| Association (many to many) | Avoid this. Deleting the many objects likely isn’t an option due to other references, and due to the danger of the cascade getting out of control. | Avoid this because the cascade is likely to get out of control. | Avoid this because the cascade is likely to get out of control. |
| Composition | Consider deleting the parts automatically when the whole is deleted. | Read in the parts automatically when the whole is read. | Save the parts automatically when the whole is saved. |
In addition to cascades, you also have the issue of ensuring that objects reference each other appropriately. For example, assume that there is a bi-direction association between Customer and Order. Also assume that the object representing Sally Jones is in memory but that you haven’t read in all of the orders that she has made. Now you retrieve an order that she made last month. When you retrieve this Order object it must reference the Sally Jones Customer object that in turn must reference this Order object. This is called the “corresponding properties” principle – the values of the properties used to implement a relationship must be maintained appropriately.
1.3 Lazy Reads
Lazy reads are a performance enhancing technique common in object-oriented applications where the values of high-overhead attributes are defined at the time they are needed. An example of a high-overhead attribute is a reference to another object, or a collection of references to other objects, used to implement an object relationship. In this situation a lazy read effectively becomes a just in time (JIT) traversal of an object relationship to read in the corresponding object(s).
What are the trade-offs between a JIT read and a cascading read? A JIT read provides greater performance because there is the potential that you never need to traverse the relationship. A JIT read is a goodstrategy when a relationship isn’t traversed very often but a bad strategy for relationships that are due to the additional round-trip to the database. A cascading read is easier to implement because you don’t need to check to see if the relationship has been initialized (it happens automatically).
1.4 Caches
A cache is a location where copies of entities are temporarily kept. Examples of caches include:
- Object cache. With this approach copies of business objects are maintained in memory. Application servers may put some or all business objects into a shared cache, enabling all the users that it supports to work with the same copies of the objects. This reduces its number of interactions with the database(s) because now it can retrieve the objects once and consolidate the changes of several users before updating the database. Another approach is to have a cache for each user where updates to the database are made during off-peak times, an approach that can be taken by fat client applications as well. An object cache can be implemented easily via the Identity Map pattern (Fowler et. al. 2003) that advises use of a collection which supports lookup of an object by its identity field (the attribute(s) representing the primary key within the database, one type of shadow information).
- Database cache. A database server will cache data in memory enabling it to reduce the number of disk accesses.
- Client data cache. Client machines may have their own smaller copies of databases, perhaps a Microsoft Access version of your corporate Oracle DB, enabling them to reduce network traffic and to run in disconnected mode. These database copies are replicated with the database of record (the corporate DB) to sync them up.
The principle advantage of caches is performance improvement. Database accesses often prove to take the majority of processing time in business application, and caches can dramatically reduce the number of database accesses that your applications need to make. How you use a cache is important. If a cache is read-only then chance are good that you don’t need to refresh it as often as you would an updateable cache. You may want to only cache data that is unlikely to change very often, such as a list of countries, but not data that is likely to change, such as customer data.
Unfortunately there are several disadvantages of caches. First, they add complexity to your application because of the additional logic required to manage the objects/data in your cache. This additional logic includes the need to refresh the cache with the database of record on a regular basis and to handle collisions between the cache and database (Implementing Concurrency Control discusses strategies for doing so). Second, you run the risk of not committing changes to your database if the machine on which a memory-based cache resides. Third, caches exacerbate cross schema referential integrity problems discussed earlier. This happens because caches increase the time that copies of an entity exist in multiple locations and thus increase the likeliness of a problem occurring.
1.5 Association, Aggregation, and Composition
There are three types of object relationships – aggregation, composition, and association – that we are interested in. Aggregation represents the concept that an object may be made up of other objects. For example, in Figure 1 you see that a flight segment is part of a flight plan. Composition is a stronger form of aggregation, typically applied to objects representing physical items such as an engine being part of an airplane. Association is used to model other types of object relationships, such as the fact that a pilot flies an airplane and follows a flight plan.
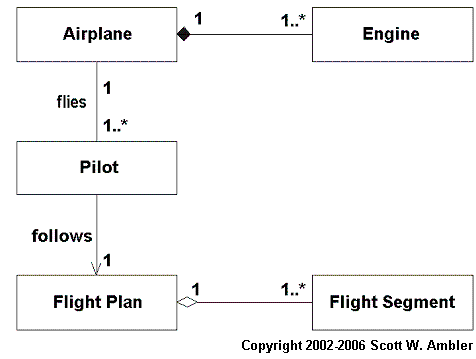
From a referential integrity perspective the only difference between association and aggregation/composition relationships is how tightly the objects are bound to each other. With aggregation and composition anything that you do to the whole you almost always need to do to the parts, whereas with association that is often not the case. For example if you fly an airplane from New York to San Francisco you also fly the engine there as well. More importantly, if you retrieve an airplane object from the database then you likely also want to retrieve its engines (airplanes without engines make little sense). Similarly a flight plan without its flight segments offer little value. You almost always want to delete the parts when you delete the whole, for example a flight segment doesn’t make much sense outside the scope of a flight plan. Association is different. A pilot object without the airplane objects that it flies makes sense, and if you delete an airplane then the pilot objects that flew it at one point shouldn’t be affected.
Clearly the type of relationship between two classes will provide guidance as to their applicable referential integrity rules. Composition relationships typically result in more referential integrity rules than does aggregation, which in turn typically results in more rules than does association.
It is important to recognize that although inheritance is a type of object relationship it isn’t a factor when it comes to referential integrity between objects. This is the result of inheritance being natively implemented by the object-oriented languages. When inheritance structures are mapped< /a>into a relational database you may end up with several tables and therefore have the normal database referential integrity issues to deal with.
1.6 Architectural Layering
Layering is the concept of organizing your software design into layers/collections of classes or components that fulfill a common purpose. Figure 2 depicts a five-layer class-type architecture for the design of object-oriented software. These layers are:
- Interface layer. A UI class implements a major UI element of your system such as a Java Server Page (JSP), an Active Server Page (ASP), a report , or a graphical user interface (GUI) screen.
- Process layer. Controller classes, on the other hand, implement business logic that involves collaborating with several domain classes or even other controller classes. In Enterprise JavaBeans (EJB)entity beans are domain classes and session beans are controller classes.
- Domain layer. Domain classes implement the concepts pertinent to your business domain such as customer or order, focusing on the data aspects of the business objects plus behaviours specific to individual objects.
- Persistence/data layer. Persistence classes encapsulate the ability to permanently store, retrieve, and delete objects without revealing details of the underlying storage technology (see the essay Encapsulating Database Access ).
- System layer. System classes provide operating-system-specific functionality for your applications, isolating your software from the operating system (OS) by wrapping OS-specific features, increasing the portability of your application.
Figure 2. Layering your system based on class types.

Architectural layering is a common design approach because it improves the modularity, and thus the maintainability, of your system. Furthermore, it is an approach that is commonly accepted within the object community and it is one of the reasons why object developers take offense to the idea of implementing business logic and referential integrity within your database.
1.7 Removal From Memory Vs. Persistent Deletions
A straightforward but important issue is the distinction between removing an object from memory and permanently deleting it from the database. You will often remove an object from memory, an act referred to as garbage collection, when you no longer require it yet you won’t delete it from the database because you’ll need it later.
2. Where Should You Implement?
You have a choice as to where you implement business logic, including your referential integrity strategy. Anyone who tells you that this logic MUST be implemented in the database or MUST be implemented in business objects is clearly showing their prejudices – this isn’t a black and white issue. You have architectural options for how you implement referential integrity as well as other types of business logic. Although it may be painful to admit, there isn’t a perfect solution. Implementing everything in business objects sounds nice in theory, but in Database Encapsulation Strategies you saw that it is common for some applications to either not use your business objects or simply be unable to due to platform incompatibilities. Implementing everything in your database sounds nice in theory, but in Database Encapsulation Strategies you also saw that it is common to have several databases within your organization, the implication being that your database really isn’t the centralized location that you want it to be. Instead of following strategies that are nice in theory you need to determine an approach that will actually work for you in practice. That’s the topic of the rest of this section.
2.1 Referential Integrity Implementation Options
There are two basic options as to where referential integrity rules should be implemented. The largest camp, the “traditionalists”, maintain that referential integrity rules should be implemented within the database. Their argument is that modern databases include sophisticated mechanisms to support RI and that the database provides an ideal location to centralize RI enforcement that all applications can take advantage of. A smaller camp, the “object purists”, maintain that referential integrity rules should be implemented within the application logic, either the business objects themselves or within your database encapsulation layer. Their argument is that referential integrity is a business issue and therefore should be implemented within your business layer, not the database. They also argue that the referential integrity enforcement features of relational databases reflect the development realities of the 1970s and 1980s, not the n-tier environment of modern architectures.
My belief is that both camps are right and that both camps are also wrong. The traditionalists’ approach breaks down in a multi-database environment because the database is no longer a centralized resource in this situation. It also ignores the need to ensure referential integrity across tiers – referential integrity is no longer just a database issue. The object purist approach breaks down when applications exist that cannot use the business layer. This includes non-object applications, perhaps written in COBOL or C, as well as object applications that simply weren’t built to reuse the “standard” business objects. The reality of modern software development, apparent even in the simplified deployment diagram of Figure 1, is that you need to find the sweet spot between these two extremes.
An agile software developer realizes that there are several options available to them when it comes to implementing referential integrity. Table 2 compares and contrasts them from the point of view of each strategy being used in isolation. The important thing to realize is that no option is perfect, that each has its trade-offs. For example, within the database community the “declarative vs. programmatic RI” debate rages on and likely will never be resolved (and that’s exactly how it should be). A second important observation is that you can mix and match these techniques. Today within your organization you are likely using all of them, and you may even have individual applications that apply each one. Once again, it isn’t a black and white world.
Table 2. Referential integrity implementation options.
| Option | Description | Advantages | Disadvantages | When to Use |
| Business objects | Programmatic approach where RI is enforced by operations implemented by business objects within your application. For example, as part of deletion an Order object will automatically delete its associated OrderItem objects. | Supports a “pure object” approach. Testing is simplified because all business logic is implemented in one place. | Every application must be architected to reuse the same business objects. Extra programming required to support functionality that is natively supported by your database. | For complex, object-oriented RI rules. When all applications are built using the same business object, or better yet domain component, framework. |
| Database constraints | This approach, also called declarative referential integrity (DRI), uses data definition language (DDL) defined constraints to enforce RI. For example, adding a NOT NULL constraint to a foreign key column. | Ensures referential integrity within the database Constraints can be generated, and reverse engineered, by data modeling tools. | Every application must be architected to use the same database, or all constraints must be implemented in each database. Proves to be a performance inhibitor with large tables. | When the database is a shared by several applications. For simple, data-oriented RI. Use in conjunction with database triggers and possibly updateable views. For large databases use during development to help you identify RI bugs, but remove the constraints once you deploy into production. |
| Database triggers | Programmatic approach where a procedure is “triggered” by an event, such as a deletion of a row, to perform required actions to ensure that other RI is maintained. | Ensures referential integrity within the database. Triggers can be generated, and reverse engineered, by data modeling tools. | Every application must be architected to use the same database, or all triggers must be implemented in each database. Proves to be a performance inhibitor in tables with large numbers of transactions. | When the database is shared by several applications. For complex, data-oriented RI. Use in conjunction with database constraints and possibly updateable views. Use during development to discover RI bugs, then remove once you deploy into production. |
| Persistence framework | Referential integrity rules are defined as part of the relationship mappings. The multiplicity (cardinality and optionality) of relationships are defined in the meta data along with rules indicating the need for cascading reads, updates, or deletions. | Referential integrity implemented as part of overall object persistence strategy. Referential integrity rules can be centralized into a single meta data repository. | Every application must be architected to use the same persistence framework, or at least work from the same relationship mappings. Can be difficult to test meta data driven rules. | For simple, object-oriented RI rules. When all applications are built using the same persistence framework. |
| Updateable Views | Referential integrity rules are reflected in the definition of the view. | Referential integrity is enforced within the database. | Updateable views are often problematic within relational databases due to referential integrity problems. Updateable views that update several tables may not be an option within your database.
All applications must use the views, not the source tables. |
When the database is shared by several applications. When your RI needs are simple.
Using in conjunction with database constraints and database triggers. |
2.2 Business Logic Implementation Options
You also have choices when it comes to implementing non-RI business logic and once again you can apply a combination of technologies. Luckily this idea does not seem to be contentious, the only real issue is deciding when to use each option. Table 3 describes each implementation option and provides guidance as to the effective application of each.
Table 3. Business logic implementation options.
| Option | Description | Advantages | Disadvantages | When to Use |
| Business objects | Business objects, both domain and controller objects, implement the business logic as a collection of operations. | Reflects standard layering practices within the development community. Business functionality easily accessible by other object applications. Very good development tools exist to build business objects. | Significant performance problems for data intensive functions. Non-object applications may have significant difficulty accessing functionality. | Complex business functionality that does not require significant amounts of data. |
| Services | An individual service, such as a web service or CICS transaction, implements a cohesive business transaction such as transferring funds between accounts. | Services can be accessed in a standard, platform independent manner. Promotes reuse. | Web services standards still evolving. Developers are still learning to think in terms of services. Need tools to manage, find, and maintain services. | Wrapper around new or existing business logic implemented by legacy systems, stored procedures, and business objects. New functionality that needs to be reused by multiple platforms. |
| Stored procedures | Functionality is implemented in the database. | Accessible by wide range of applications. | Potential for database to become a processing bottleneck. Requires application programmers to have significant database development experience in addition to “normal” application development experience. Very difficult to port between database vendors. | Data intensive functions that produce small result sets. |
For years I have advised developers to avoid using stored procedures because they aren’t portable between databases. During the 1990s I had been involved with several initiatives that had run into serious trouble because they needed to port to a new database in order to scale their application, and as a result they needed to redevelop all of their stored procedures. Ports such as this were common back then because the database market hadn’t stabilized yet. It wasn’t clear back then what products were going to survive and as a result organizations hadn’t committed yet to a single vendor. Times have changed. Most database vendors have solved the scalability issue make it unlikely that you need to port. Furthermore most organizations have chosen a primary database vendor – it is quite common for an organization to be an “Oracle shop”, a “DB2 shop”, or a “MySQL shop” – making it unlikely that you will be allowed to port anyway. Therefore stored procedures, assuming that they are well written and implemented according to the guidelines described below, are now a viable implementation option in my opinion. Use them wisely.
2.3 General Implementation Strategies
In the previous sections you have seen that you have several technical alternatives for implementing referential integrity and other business logic. You have also seen that each alternative has its strengths and weaknesses. This section overviews several strategies that you should consider when deciding where to implement this logic. These strategies are:
- Recognize that it isn’t a black and white decision. I simply can’t say this enough – your technical environment is likely too complex to support a “one size fits all” strategy.
- Implement logic on commonly shared tier(s). The best place to implement commonly used logic is on commonly used tiers. If your database is the only common denominator between applications, this is particularly true when applications are built on different platforms or with different technologies, then your database may be your only viable option to implement reusable functionality.
- Implement unique logic in the most appropriate place. If business logic is unique to an application implement it in the most appropriate place. If this happens to be in the same place that you’re implementing shared logic then implement it in such a way as to distinguish it and better yet keep it separate so that it doesn’t “get in the way” of everyone else.
- Implement logic where it’s easiest. Another factor you need to consider is ease of implementation. You may have better development tools, or more experience, on one tier than another. All things being equal, if it’s easier for you to develop and deploy logic to your application server than it is into your database server then do so.
- Be prepared to implement the same logic in several places. You should always strive to implement logic once, but sometimes this isn’t realistic. In a multi-database environment, you may discover that you are implementing the same logic in each database to ensure consistency. In a multi-tier environment you may discover that you need to implement most if not all of your referential integrity rules in both your business layer (so that RI rules are reflected in your object schema) and your database.
- Be prepared to evolve your strategy over time. Some database refactorings include moving functionality into or out of your database. Architectural direction – it might be painful, but you may want to eventually stop implementing business logic in some places.
However, having said all this the reality is that databases are often the best choice for implementing RI. The growing importance of web services and XML point to a trend where application logic is becoming less object-oriented, even though object technology is the primary underlying implementation technology for both, and more data-processing oriented. Nevertheless your team still needs to work through this critical architectural issue.