
UML Data Model Profile: A Practical Notation
Data modeling is not yet covered by the Unified Modeling Language (UML), even though persistence-related issues are clearly an important aspect of object-oriented software initiatives. For many years I have argued that the UML needs a data model (first in Building Object Applications that Work in 1997 and most recently in Refactoring Databases) and have vacillated between various ways that it should be done. Other methodologists have argued the same (Naiburg and Maksimchuk 2001, Muller 1999) because they recognize the clear need to extend the UML. Unfortunately, we have all come up with slightly different modeling notations, a problem that the UML is supposed to address, if my memory serves me correctly. This page summarizes an unofficial profile for a UML data model that is based on UML Class Diagrams. I apply this profile on this site and in the books Agile Database Techniques, The Object Primer 3rd Edition, and Refactoring Databases.
First some important definitions:
- Logical data models (LDMs). LDMs are used to explore either the conceptual design of a database or the detailed data architecture of your enterprise. LDMs depict the logical data entities, typically referred to simply as data entities, the data attributes describing those entities, and the relationships between the entities.
- Physical data models (PDMs). PDMs are used to design the internal schema of a database, depicting the data tables, the data columns of those tables, and the relationships between the tables.
- Conceptual data models. These models are typically used to explore domain concepts with stakeholders. Conceptual data models are often created as the precursor to LDMs or as alternatives to LDMs.
This profile follows the strategy of separating core notation, the 20% that you are likely to use in practice, from supplementary notation that isn’t as common although still needed in some situations. The notation presented here isn’t perfect but I truly believe that it’s the best source available to you today. Nor is this profile complete – for the most part it focuses on the physical modeling of a relational database, although it does cover other aspects of data modeling as needed. This profile also strays into style issues, something that is not appropriate for a proper UML profile, issues that in my opinion are critical to successful modeling and this in my opinion is the best place to present them.
Table of Contents
- How do I indicate the type of model?
- How do I model tables, entities, and views?
- How do I model relationships?
- How do I model data attributes and columns?
- How do I model keys?
- How do I model constraints and triggers?
- How do I model stored procedures?
- How do I model sections within a database?
- How do I model “suggested access”?
- How do I model everything else?
- Notation Summary for UML Physical Data Modeling
- The requirements for this profile
- Where do we go from here: Evolving this profile?
- Linking to this page
- Contributors to the profile
1. How Do I Indicate The Type Of Model?
The type of model should be indicated either using the appropriate stereotype listed in Table 1 or simply as free form text in a UML note. In the case of a physical data model the type of storage mechanism should be indicated with one of the stereotypes listed in Table 2 .
Table 1. Stereotypes to Indicate Model Types (Core notation).
| Stereotype | Model Type |
| <<Class Model>> | Object-oriented or object-relational model |
| <<Conceptual Data Model>> | Conceptual data model |
| <<Domain Model>> | Domain model |
| <<Logical Data Model>> | Logical data model (LDM) |
| <<Physical Data Model>> | Physical data model (PDM) |
Table 2. Stereotypes for Various Persistent Storage Mechanisms (Supplementary Notation).
| Stereotype | Storage Mechanism Type |
| <<File>> | File |
| <<Hierarchical Database>> | Hierarchical database |
| <<Object-Oriented Database>> | Object-oriented database (OODB) |
| <<Object-Relational Database>> | Object-relational database (ORDB) |
| <<Network Database>> | Network database |
| <<Relational Database>> | Relational database (RDB) |
| <<XML Database>> | XML database |
2. UML Data Model: How Do I Model Tables, Entities, And Views?
Tables, entities, and views are all modeled using class boxes, as you see in Figure 1 and Figure 2, and the appropriate stereotypes are listed in Table 3. Class boxes that appear on conceptual and logical data models are by definition entities so the stereotype is optional. Similarly, on a physical data model for a relational database it is assumed that any class box without a stereotype is a table. In Figure 2 you see that views have dependencies on the table structures.
Indices, shown in Figure 2, are also modeled using class boxes. They are optionally dependent on either the table for which they are an index or on the actual columns that make up the index (this is more accurate although can be more complex to depict when the index implements a composite key). In the model you see that IEmployee1 is dependent on the Employee_POID column whereas IEmployee2 is dependent on just the table, requiring you to list the columns for the index when you follow this style. As you can see the notation used for IEmployee2 is wordier but less clumsy – if you’re going to model indices this should your preference with respect to style issues.
Figure >1. A logical data model.
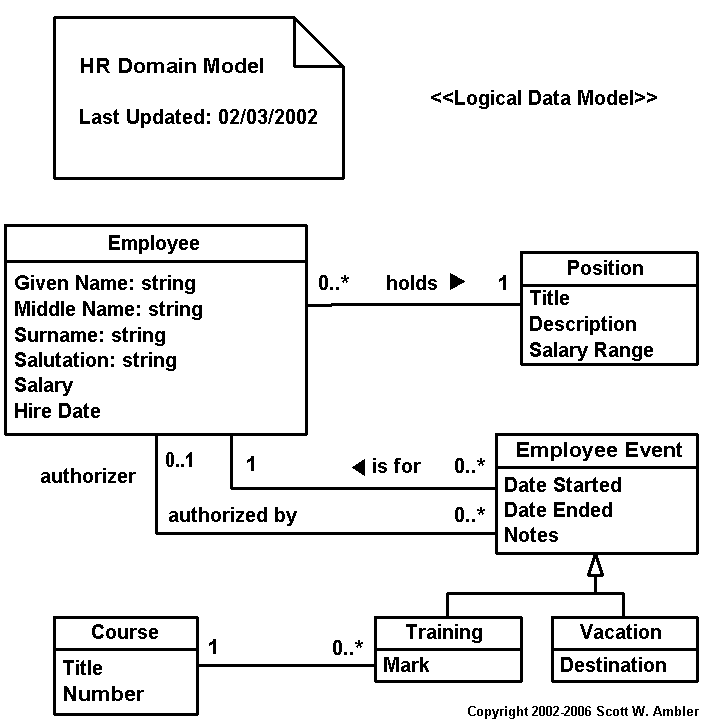
Figure 2. A physical data model for a relational database.
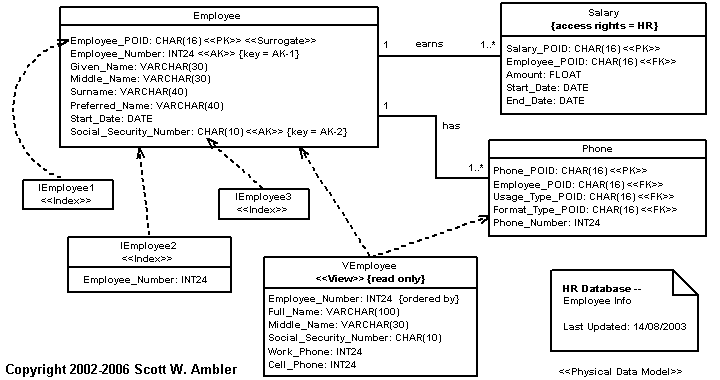
Table 3. Stereotypes for Classes.
| Stereotype | Diagram Type | Core Notation | Application | Style Issues |
| <<Associative Table>> | Physical | Yes | Apply this to associative tables in a PDM for a relational database. | |
| <<Entity>> | Logical, Conceptual | No | Optional notation that is implied by the model type. | The stereotypes for LDMs and conceptual DMs on a diagram implies that all class boxes on the diagram are entities unless otherwise marked. |
| <<Index>> | Physical | No | Apply this when you are modeling an index that implements a table key within a relational database. Doing so indicates a dependency from the index to the table or to the key column(s) that the index implements. | Indices are implied by keys, so you might not want to invest the time to model the index in the first place. |
| <<Lookup Table>> | Physical | No | Apply to tables that are used to store simple “lookup” lists. | Just because you are using a table for lookup values does not imply that everyone uses it that way. Therefore you may not wish to mark the table with this stereotype as it may confuse people. |
| <<Stored Procedures>> | Physical | Yes | Apply this to a class that contains only the operation signatures for the stored procedures of the database. | |
| <<Table>> | Physical | No | Optional notation that is implied by the model type. | The stereotype for PDMs on a diagram implies that all class boxes on the diagram are tables unless otherwise marked. |
| <<View>> | Physical | Yes | Apply this when you are modeling a view to a table. Indicate a dependency to each table involved in the definition of the view. |
3. How Do I Model Relationships in UML Data Models?
Relationships are modeled using the notation for associations as you can see in Figure 1 and Figure 2. Standard multiplicity (e.g. 0..1, 1..*, and 2..5) notation may be applied, as can roles. Table 4 lists the potential stereotypes that you may apply to relationships, some of which have a common visual representation as well as a textual one. In general Iprefer to apply the visual stereotype over the textual one. The notation for qualifiers shouldn’t be used. Although it would be a valid option to model foreign keys in practice this often proves confusing when a single table is involved in many relationships.
Table 4. Stereotypes for Associations.
| Stereotype | Visual Stereotype | Diagram Type | Core Notation | Application | Style Issues |
| <<Subtype>> | Inheritance arrow | All | Yes | Indicate subtype/supertype or inheritance relationships between two entities. | |
| <<Aggregation>> | Hollow diamond | All | No | Indicate an aggregation relationship between two entities. | Aggregation is not supported in UML 2.0. I suspect that it will be reintroduced in a future version. |
| <<Composition>> | Filled diamond | All | No | Indicate a composition relationship between two entities. | |
| <<Dependency>> | Dashed line with open arrowhead | Physical | Yes | Indicate a dependency of a view or index on the schema of a table. | I would model the dependency from the view/index to the table(s) it is dependent on. I would not model the dependency at the column level, even though that is truly where it is, because your diagrams would become cluttered very quickly. |
| <<Identifying>> | None | Physical | No | Indicate an identifying relationship between two dependent tables (the child table cannot exist without the parent table). | Indicating whether a relationship is identifying or not really isn’t all that useful in practice. |
| <<Uni-directional>> | Open arrowhead | All | No | Indicate that the relationship between two entities should only be traversed in a single direction. | |
| <<Non-Identifying>> | None | Physical | No | Indicate a non-identifying relationship between two independent tables. |
4. How Do I Model Data Attributes and Columns in UML Data Models?
Data attributes on conceptual and logical data models, as well as columns on physical data models, are modeled using the standard attribute notation. It is optional to model the type of an attribute on a conceptual or logical data model although in practice this is often done. Stylistically, if the model is being used to model data requirements then the type should be indicated only when it is an actual requirement. For example, if a customer number must be alphanumeric then indicate it as such, otherwise if it is optional how this attribute is implemented then do not indicate the type.
Constraints, such as a column being not null, should be modeled using normal UML constraints (see below).
The notation for visibility shouldn’t be used – the assumption is that the data is publicly accessible. Although visibility symbols could be used to indicate the need to indicate access control this is better done using constraints.
An important issue which should be addressed for a column is whether it is a suggested source of information.
5. How Do I Model Keys in UML Data Models?
In my opinion, the modeling of keys is the the most complicated issue addressed by this profile. This is for several reasons:
- An entity can have several candidate keys, each of which may be composite.
- A table can have a primary key and several alternate keys, each of which can be composite.
- The order in which the columns appear in table keys can be important.
- Traditional data models typically don’t have a good way of distinguishing which key an attribute or column is a part of, this information is often left for supporting documentation.
As you can see in Figure 3 the notation for indicating keys can get quite complex. Minimally, you should mark the attribute or column with one of the key-oriented stereotypes in Table 5 . Although I would normally prefer stereotypes such as <<Primary Key>> over <<PK>>, I chose the abbreviated version because it reflects existing norms within the data community for indicating keys. Furthermore, because some columns can be involved with several keys the longer form of the stereotype would become cumbersome.
It is optional to model the detailed information pertaining to keys using UML tagged values (described in in Table 6). For example, in Figure 3 you see that:
- The Order_ID column is the first element of the primary key.
- Order_Item_Sequence is the second element of the primary key.
- Order_ID is part of several keys, therefore I needed to indicate additional information where appropriate. For example, Order_ID is the second element of the first alternate key.
- Because Order_Item_Sequence is part of a single key I didn’t need to indicate the order.
- Item_ID is the first element of the first alternate key.
- Item_ID is also a foreign key to the Item table.
In Figure 2 I indicated that Employee_POID is a surrogate key to provide an example of how to do this (had it been a natural key I would have applied the stereotype <<Natural>> instead). I generally prefer to indicate whether a key auto generated, natural, or surrogate in the documentation instead of on the diagrams – this is an option for you although in my opinion this sort of information adds to much clutter.
Figure 3. Modeling keys, constraints, and behaviors on a physical data model.
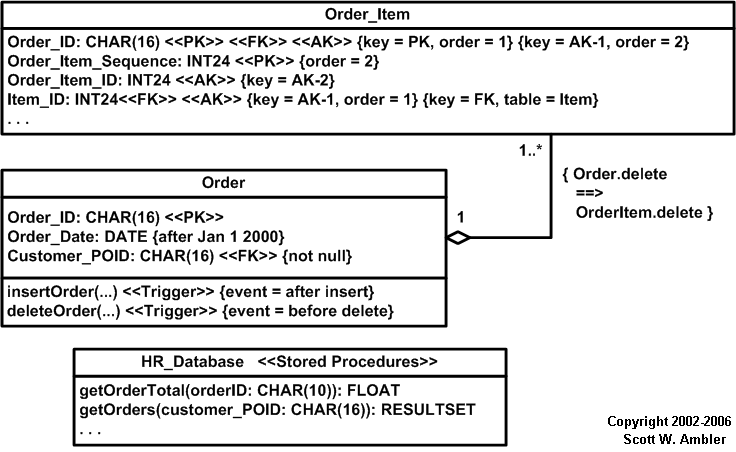
Table 5. Stereotypes for columns.
| Stereotype | Diagram Type | Core Notation | Application | Style Issues |
| <<AK>> | Physical | Yes | Indicates that a column is part of an alternate key, also known as a secondary key, for a table. | |
| <<Auto Generated>> | Physical | No | Indicates that the column value is automatically generated by the database. | This is interesting information, but I don’t think I’d clutter the diagram with it. |
| <<CK>> | Conceptual, Logical | Yes | Indicates that an attribute is part of a candidate key for an entity. | |
| <<Column>> | Physical | No | Indicates that an attribute is a column. | Completely redundant information, I wouldn’t even consider modeling this. |
| <<FK>> | Physical | Yes | Indicates that a column is part of a foreign key to another table. | |
| <<Natural>> | All | No | Indicates that an attribute or column is part of a natural key. | Interesting information, but don’t clutter your diagram with it. |
| <<Not Null>> | Physical | Yes | Indicates at a column may not have null values. | |
| <<Nullable>> | Physical | Yes | Indicates that a column can have null values. | |
| <<PK>> | Physical | Yes | Indicates that a column is part of a primary key for a table. | |
| <<Surrogate>> | Physical | No | Indicates that a column is a surrogate key. | Interesting information, but don’t clutter your diagram with it. |
| <<Unique Identifier>> | Conceptual, Logical | No | Indicates that an attribute is part of a unique identifier for an entity. Effectively an alternative to <<CK>>. | Perfer <<CK>> over this stereotype. |
Table 6. Tagged values for modeling keys (supplementary notation).
| Value | Application | Examples | Style Issues |
| key | Indicate which candidate or alternate key an attribute/column belongs to. When the column is part of several keys, for example it is part of two different foreign keys, then you need to indicate which one you are referring to. In the second example the column is part of the third alternate key. | key = FK
key = AK-3 |
Only indicate this when the column is part of more than one key. |
| order | Indicate the order of appearance in which an attribute appears when it is part of a composite key. In the example the column would be the fourth column in the key. | order = 4 | |
| source column | Indicate the source column that a foreign key refers to. | source column = SocialSecurityNumber | Only use this when the names of the two columns are different. |
| table | Indicate the table that a foreign key refers to. | table = Customer | This is optional as it can often be inferred from the diagram. |
6. How Do I Model Constraints And Triggers in UML Data Models?
Most constraints (domain, column, table, and database) can be modeled using the UML’s Object Constraint Language (OCL) where appropriate. Examples of this are depicted in Figure 3, a domain constraint on the Order_Date is defined indicating that it must be later than January 1st 2000. A column constraint is also defined, the Customer_POID column mustn’t be null.
Table and database constraints (not shown) are be modeled the same way. For example Figure 3 depicts how a referential integrity (RI) constraint can be modeled between two tables using OCL notation. You see that when an order is deleted the order items should also be deleted. Although this implied by the fact that there is an aggregation relationship between the two tables the constraint makes this explicit. However, too many RI constraints can quickly clutter your diagrams, therefore supporting documentation for your database design might be a better option for this information so as not to clutter your diagrams – remember AM’s Depict Models Simply practice.
In Figure 2 the Salary table includes an access control constraint, only people in the HR department are allowed to access this information. Other examples in this diagram include the read only constraint on the VEmployee view and the ordered by constraint on Employee_Number in this view.
Triggers are modeled using the notation for methods(operations). In Figure 3 you see that the stereotype of <<Trigger>> was applied and tagged value of “after insert” and “before delete” were modeled to shown when the triggers would be fired. Stereotypes for methods are listed in Table 7.
Table 7. Stereotypes for methods.
| Stereotype | Diagram Type | Core Notation | Application | Style Issues |
| <<Stored Procedure>> | Physical, Relational Databases | No | Indicates that a method is a stored procedure. | Stored procedures should be modeled as part of a single class. This class is marked with the stereotype <<Stored Procedures>>, therefore you are merely cluttering your diagram with extraneous information by also applying a stereotype to the method. |
| <<Trigger>> | Physical, Relational Databases | Yes | Indicates that the method is a trigger. | You should also model the event that triggers the method. e.g. {event = before insert | after update, target = ColumnName} |
7. How Do I Model Stored Procedures in UML Data Models?
Stored procedures should be modeled using a single class with the stereotype <<Stored Procedures>> as shown in Figure 3 and described in Table 3. This class lists the operation signatures of the stored procedures using the standard UML notation for operation signatures.
Although it is standard UML practice for stereotypes to be singular, in this case the plural form makes the most sense. The other alternative is to apply the stereotype <<Stored Procedure>> to each individual operation signature, something that would unnecessarily clutter the diagram.
Stylistically, the name of this class should either be the database or the name of the package within the database.
8. How do I Model Sections Within a Database in a UML Data Model?
Many database management systems provide the ability to segregate your database into sections. In Oracle these sections are called tablespaces and other vendors call them partitions or data areas. Regardless of the term, you should use a standard UML package with a stereotype which reflects the terminology used by your database vendor (e.g. <<Tablespace>>, <<Partition>>, and so on).
9 How Do I Model Suggested Access?
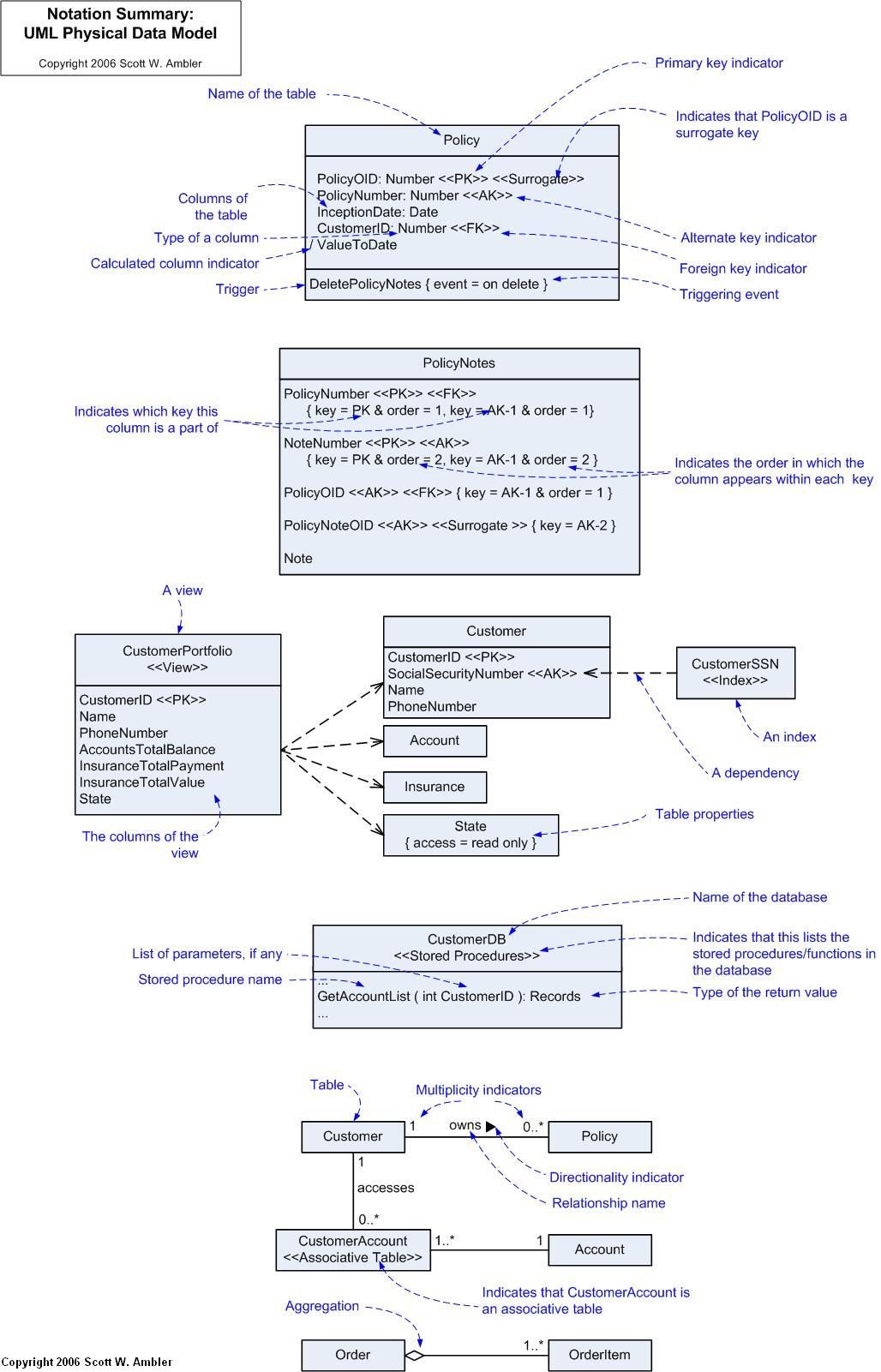
For the sake of discussion in this section, a storage element is somewhere that you store data such as a column, table, or database and a database element is a storage element plus any non-storage elements such as stored procedures and views. A storage element potentially has suggested levels of access. For example, it may be the source of record and therefore it is highly suggested the people use it. It may be a copy of data from another source, a copy that may or may not be automatically replicated, or it may be deprecated and therefore it is suggested that the database element is not accessed at all. Table 8 provides suggestions for how to indicate this information and Figure 4 an example.
Table 8. Indicating suggested access.
| Visual Stereotype | Stereotype | Application |
| Checkmark | <<source of record>> | Indicates that the storage element is the, or one of them, source(s) of record. |
| c | <<copy>> | Indicates that the storage element is a copy of another storage element. Ideally there should also be a dependency indicated from the copy to the source of record. |
| <<replicated from>> | Indicates that a copy of a storage element is replicated from another storage element. This stereotype is applied to a dependency. | |
| x | <<deprecated>> | Indicates that the database element has been deprecated and is scheduled for removal. Ideally there should be a dependency to the suggested database element (if any) and a removal date indicated. Deprecation of database elements is a common aspect of the process of database refactoring. |
10. How Do I Model Everything Else?
There is far more to data modeling than what is covered by this profile. The approach that I’ve taken is to identify the type of information that you are likely to include on your diagrams, but this is only a subset of the information that you are likely to gather as you’re modeling. For example, logical data attribute information and descriptions of relationships can be important aspects of logical data models. Similarly replication info (e.g. which tables get replicated, how often, “¦), sizing information (average number of rows, growth rate, “¦), and archiving information can be critical aspects of your physical data model. Complex business rules are applicable to all types of models. Although this information is important, in my opinion it does not belong on your diagrams but instead in your documentation. Follow AM’s practice of Depict Models Simply by keeping this sort of information out of your diagrams.
If you feel there is something missing from this profile, and there definitely is, then let’s talk about it.
11. Summary of UML Data Model Notation for Physical Data Models
I originally developed Figure 4 for the inside cover of Refactoring Databases (which uses this notation throughout the book). I thought it might be a good reference diagram.
12. Requirements For This Profile
I firmly believe that the requirements for something should be identified before it is built. This is true of software-based systems and it should be true for UML profiles (even unofficial ones). This section presents a bulleted list of requirements from which I worked when putting this profile together. I have chosen to present the requirements last because I suspect most people are just interested in the profile itself and not how it came about.
If anyone intends to extend this profile I highly suggest that they start at the requirements just as I have. The high-level requirements are:
Need to support different types of models
- Conceptual, logical, and physical data models
- Need to support different types of data storage mechanisms (e.g. relational, object, XML, “¦)
Need to model entities and tables
- Entities appear on logical and conceptual data models
- Tables appear on physical data models for RDBs
- Users/programs may have different levels of access to a table, including none, read-only, update, insert, and delete.
Need to model the attributes and columns
- The type of the attribute/column
- Need to support derived data
- Different databases have different possible types
- Some types have sizes (e.g CHAR) whereas with others the size is implied (e.g. Double)
- Tables have one or more columns
- Entities have one or more attributes
- System columns are only accessible by the system itself
- Data columns are accessible to any user/program granted rights to access the column
- Users/programs may have different types of access to a column, including read and update access
Need to model relationships
- Referential integrity rules
- Identifying relationships
- Non-identifying relationships
- Inheritance
- Aggregation
- Composition
Need to model keys
- Candidate keys
- Primary keys
- Alternate/secondary keys
- Foreign keys
- A table has zero or one primary key
- A table has zero or more secondary keys
- A table must have a primary key to have a secondary key
- A key is composed of one or more columns
- A key composed of two or more columns is called a composite key (terminology issue)
- Any given column may be a part of zero or more keys
- Associations between tables are implemented as foreign keys
- Any given column could be part of different types of keys (e.g. Column A is part of the primary key for a table and the foreign key to another table)
- Logical models indicate candidate keys
- Physical models indicate primary and alternate keys
- Some keys may be natural (e.g. Invoice Number) whereas others are surrogate (e.g. a persistent object identifier (POID) )
Need to model constraints and behaviors
- Triggers
- Need to model stored procedures
- Stored procedures can access data stored in zero or more tables
- Access control rules
Need to model source of record/access
- Indicate that a column/table/db is the, or at least one of, the official source of record
- Indicate that a database element has been deprecated
- Indicate the suggested database element which replaces a deprecated element
- Indicate that a column/table/db is a copy of another
13. Where Do We Go From Here: Evolving this UML Data Model Profile?
We don’t.
14. Linking to this Page
If you find this information useful, or at least you think it is something that your colleagues may benefit from, please feel free to link to it. This will help to get the word out within the community. The more people that know about and use this notation the greater the chance that member of the OMG will take up and finish this work.
Suggested listing:
Title: A UML Profile for Data Modeling (Scott W. Ambler)
URL: AgileData.org/essays/umldatamodelingprofile.html
15. Contributors to this Profile
On November 2, 2003 I added this section to identify who has provided input into this profile.
- Scott Ambler
- Eric Hartford
- Andreas Rueckert